0x00 前言
本文用识别由域名生成算法Domain Generation Algorithm: DGA生成的C&C域名作为例子,目的是给白帽安全专家们介绍一下机器学习在安全领域的应用,演示一下机器学习模型的一般流程。机器的力量可以用来辅助白帽专家们更有效率的工作。
本文用到的演示数据集和python演示代码请参见https://github.com/phunterlau/dga_classifier关于编码和行文风格过于仓促的问题,请不要在意这些细节,如果有相关问题可以微博上@phunter_lau,大家互相交流进步。
0x01 为什么要机器学习?
DGA生成C&C域名的办法常见于一类botnet,比如conficker,zeus之类,他们的方法是用一个私有的随机字符串生成算法,按照日期或者其他随机种子(比如twitter头条),每天生成一些随机字符串域名然后用其中的一些当作C&C域名。在他们的bot malware里面也按照同样的算法尝试生成这些随机域名然后碰撞得到当天可用的C&C域名。
多数关于C&C域名的研究在于部分特性比如域名的快速转换(fast flux)或者是分析malware的源码找出随机算法(或者像zeus这样源码泄漏)。而对于一个白帽子专家来说,可能把域名给他看一下他也就能按照经验猜出来大概,比如我们可以猜猜下面哪些域名可能是C&C域名:
fppgcheznrh.org
fryjntzfvti.biz
fsdztywx.info
yahoo.com.
baidu.com.
dmiszlet.cn
dmgbcqedaf.cn
google.com.
facebook.com.
frewrdbm.net
上面的例子混合了常见合法域名和confickr生成的一些C&C域名,白帽可以用多年人生的经验轻松分辨,但大量随机域名由机器生成,我们不能雇佣十万个白帽专家挨个检测,就好比观众朋友们可能看完上面10个域名就已经眼花了。
机器可以利用人类的经验来完成这样的重复性工作,比如分类(Classification)任务就是判别一个域名是不是C&C,判别一个狗咬不咬人,这些Yes or No的任务都是分类任务。分类任务归于是机器学习里面的监督学习(supervised learning),基本套路就是:
- 提供训练数据集
- 把人类的经验表示为特征(feature)把数据集转换成特征向量(feature vector)
- 利用这些数据集和他们的特征向量训练合适的分类器(Classifier,不用担心,这一步有无数开源工具)
- 评价分类效果,比如精度、召回率等等,并交叉检验分类效果 (Cross-validation)。
机器学习并没有什么神秘的技术,它本质上是用多个变量进行综合决策,机器在这多个变量的约束下用数值计算方法找出近似最优解。比如在这个例子里,白帽专家的经验就是“这些域名看起来像是随机的”。如果把“看起来”表示称机器能计算的多个变量的特征,机器就能帮助白帽专家判别哪些域名可能是C&C域名。
0x02 数据收集
分类的任务需要告诉机器他用来学习的正例(positive samples)和反例(negative samples),在这里正例就是C&C域名,反例就是正常的合法域名。
正例和反例的涵盖范围和具体问题有关,具体到本文的例子,我选择Conficker(ABC三种混合)当作正例,Alexa前10万当作反例。Conficker的算法早在多年前公开,这里纯粹是演示目的并没有产品化的意义,对于实际的工作如果想让模型有更广泛的适用性,需要在训练数据集里加入其他种类的C&C域名以及其他合法域名,然后用类似的办法训练得到一个更广泛适用的模型。
整理好的数据集在:conficker_alexa_training.txt格式是第一列为域名(字符串),第二列为它的标记(0代表反例,1代表正例)
0x03 特征工程
这几乎是整个文章最有值得读的部分。如果能把人类的经验用数量化表达给机器,机器就能学习到人类的经验,而特征(feature)就是人类经验的数量化。特征工程是个反复循环的过程,一开始我们找到基线特征,用分类算法计算并评价结果,如果结果不能达到预期,再回头来加入新的特征帮助更好的分类。
基本特征:随机性和熵
我们可以想一下,具体为什么C&C域名看起来和别的合法域名比如google.com不一样呢?因为它看起来随机,所以第一个特征就是找一个数量来描述它的随机性。我们用Shannon熵http://en.wikipedia.org/wiki/Entropy_(information_theory)表达域名里各个字符出现的随机性,因为越是随机熵值越高:
from collections import Counter
count = Counter(i for i in main_domain).most_common()
entropy = -sum(j/f_len*(math.log(j/f_len)) for i,j in count)#shannon entropy
Shannon熵可以很好的判别fryjntzfvti.biz和google.com/qq.com之间的区别,因为前者用了很多不重复字母而qq.com的重复字幕比较多。但是很多合法域名的熵值和C&C域名之间的并非是绝对差距,比如baidu.com也是五个不重复的字母,这单个特征不足以最终决策,我们还一些其他高级的特征。
高级特征:还有什么能表达随机性呢
合法域名一般比较好念出来,C&C域名不好念
思考一下合法域名和C&C域名的目的,就可以想到:合法域名为了让人类记住会选一些好念(pronounceable)的域名,比如 google yahoo baidu等等有元音字母之类好念的,而C&C域名为了随机性就不太好念,比如fryjntzfvti.biz。域名里元音字母占的比重可以是个很好的特征。
“好念“这个概念也可以有另外一个高级一些的特征,叫做gibberish detection,判断一个字符串是不是能用人类的语言念出来,比如google就不是一个英文单词但是朗朗上口。这背后是一个基于马尔可夫链的模型,具体细节可以参见https://github.com/rrenaud/Gibberish-Detector
连续 vs 分散
通过进一步观察我们可以发现,C&C域名的随机性也表现在连续出现的字母和数字上。一般随机生成的域名都不会出现大段连续的数字或者连续出现相同的字母。同时因为英文字母分布里辅音字母远多于元音字母,C&C更可能连续反复出现辅音字母,而合法域名为了好念多是元音辅音交替。这些都是不容易想到但是容易计算的特征,代码并不复杂。
还有什么?n-gram 的平均排名!
这是我个人认为比较巧妙的想法。
对于字符串文本的机器学习,n-gram (unigram(单字)bigram(相邻双字)trigram(相邻三字))常常能提供重要的特征。举例来说,fryjntzfvti.biz的域名的bigram分解是以下12个:
^f,fr,ry,yj,jn,nt,tz,zf,fv,vt,ti,i$
这里^和$代表字符串的开头和结尾。观众朋友可以自行计算trigram当作练习。bigram/trigram本身出现的频率也可以当作特征,但是对这个问题来说,bigram本身可能有 (26+2)^2=784种组合,trigram就有21952种组合,特征向量的长度太长而我们的数据约有25万组,如果把他们本身当作特征,模型训练的速度很慢。(比较熟悉机器学习的观众朋友可能会提示用PCA等降维方法,我实际实验表明降维到20维左右效果也不错,在此不当作本文内容,请有兴趣的观众朋友自己实验一下。)
C&C域名的随机算法产生的bigram和trigram比较分散,而合法域名喜欢用比较好念好见的组合。如果把正例反例出现的bigram按照出现频率进行排序会发现,合法域名的bigram在频率排序里的位置比较靠前,而随机C&C域名产生的比较分散的bigram/trigram基本上频率都很低,所以bigram/trigram的平均排名也可以很好的区分C&C和合法域名。
扯一些额外内容。n-gram的分析方法也常用于malware的代码和二进制码的自动分析,比如ASM里面每个指令当作一个gram,指令的组合可能对应于一些可疑行为。靠人工找这些可能可疑行为对应的指令组合十分麻烦,但是机器就适合做这些繁琐的事情啊,只要把所有n-gram扔给机器做分类,最后机器会给出特定组合的权重,就能找到这些对应的指令对了。二进制代码的分析也有类似方法,参见最近Kaggle的malware分类比赛的获胜报告(参考文献3)。有白帽专家可能会问,有些可疑指令对可能距离比较远怎么办?这种情况就是skip-gram分析,建议谷歌搜索相关关键词,这里就不多说撑篇幅了。
究竟还能再挖出来什么特征呢?
特征工程就好像Taylor Swift的胸一样,你只要需要,用力挤努力挤还是有的。如果按照反例Alexa前10万名训练隐含马尔可夫链,计算一下从A_i到A_i+1转换的概率。这个转换概率的分布对于正例有一些区别,也可以用来帮助区分。具体关于马尔可夫链相关知识请参见http://en.wikipedia.org/wiki/Markov_chain(解释起来背后的原因篇幅比较大,就只贴一下这个特征的分布图,但是不要害怕,看示例代码里的实现其实很简单,只是计算转移矩阵而已)
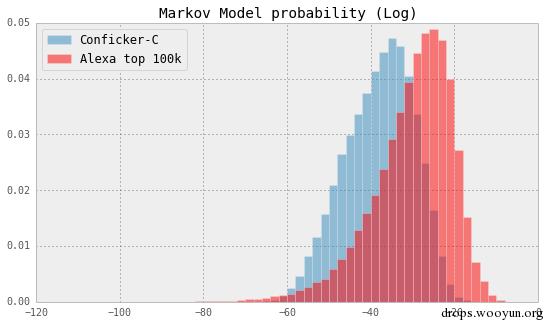
领域特征:安全专家的领域知识
对于C&C域名,不只是随机性,其他白帽专家才知道的领域知识也会提供重要的特征。
比如域名所在的ccTLD可以当作特征。我们知道多数情况下.com的域名申请又贵又要审核,所以现在很多C&C不会选择.com,反而会选一些审核不严的比如.biz .info .ru .ws以及最近爆发的.xyz之类的ccTLD都是C&C重灾区。中国的白帽专家也可能知道.cn现在申请都得备案,所以C&C也不太可能用.cn的根域名当作C&C。值得提醒的是,这些情况并非100%确定,比如C&C可能找到一个cn域名的下级域名当C&C而主域名已备案,这些需要机器综合考虑其他特征来判断。ccTLD这样的类别特征(categorial feature)在使用的时候需要编码变成 is_biz=0/1, is_ws=0/1这样展开的0/1向量,这个方法叫做OneHotEncoder。实际的模型结果也显示出来.biz .info之类的ccTLD对C&C域名的判断占的重要性比重很大。
还有一些看似比较无聊但是很有价值的知识:比如C&C域名现在越来越长,因为短的域名都被抢光了,所以域名长度也可以是重要的特征。更多这些特征需要安全专家加入自己的领域知识来得到,专家的领域知识在机器学习里的重要程度几乎是第一位的。
Talk is cheap, show me the code!
特征工程部分的代码流程如下
-
tld_appender.py(解析每个域名的ccTLD) -
gram_freq_rank.py(生成bigram/trigram的基准排名) -
feat_n_gram_rank_extractor.py(得到bigram/trigram排名) -
feat_extractor.py(各个特征计算的函数,需要包含https://github.com/rrenaud/Gibberish-Detector) -
feat_normalizer.py和feat_vectorizer.py(特征归一化向量化)
最后会输出vectorized_feature_w_ranks_norm.txt的归一化向量化的结果文件。对于25万组数据,这个文件比较大,就没有包含在github代码库里了,请自行生成。
这些是上面谈到的各个特征在在代码里的入口,完整的代码请参见github:
#in feat_extractor.py
f_len = float(len(main_domain))
count = Counter(i for i in main_domain).most_common()#unigram frequency
entropy = -sum(j/f_len*(math.log(j/f_len)) for i,j in count)#shannon entropy
unigram_rank = np.array([gram_rank_dict[i] if i in gram_rank_dict else 0 for i in main_domain[1:-1]])
bigram_rank = np.array([gram_rank_dict[''.join(i)] if ''.join(i) in gram_rank_dict else 0 for i in bigrams(main_domain)])#extract the bigram
trigram_rank = np.array([gram_rank_dict[''.join(i)] if ''.join(i) in gram_rank_dict else 0 for i in trigrams(main_domain)])#extract the bigram
#linguistic feature: % of vowels, % of digits, % of repeated letter, % consecutive digits and % non-'aeiou'
vowel_ratio = count_vowels(main_domain)/f_len
digit_ratio = count_digits(main_domain)/f_len
repeat_letter = count_repeat_letter(main_domain)/f_len
consec_digit = consecutive_digits(main_domain)/f_len
consec_consonant = consecutive_consonant(main_domain)/f_len
#probability of staying in the markov transition matrix (trained by Alexa)
hmm_prob_ = hmm_prob(hmm_main_domain)
一个技巧是,因为有ccTLD这个离散特征,我们把所有的特征用字典dict存储,然后用scikit-learn的DictVectorizer将特征向量化:
#in feat_vectorizer.py
from sklearn.feature_extraction import DictVectorizer
vec = DictVectorizer()
measurements = [feat_dict for domain,cla,feat_dict in feat_table]
feature_list = vec.fit_transform(measurements).toarray()
值得再次提醒注意的是,特征工程是个反复的过程,不用在一开始就找到足够多的好的特征。在我的实际实验里,后面的高级特征也花了好几天的时间反复思考得到。
0x04 模型选择和训练
判断一个域名是不是C&C域名这样Yes or No任务是分类任务。对于分类任务,常见的模型一般是Logistic Regression啊决策树啊之类的。这里我选择SVM支持向量机作为分类算法,关于SVM的理论知识可以前往http://en.wikipedia.org/wiki/Support_vector_machine阅读了解,而我们用起来它只需要:
#!python
from sklearn.svm import SVC
classifier = SVC(kernel='linear')
就可以创建一个SVM的线性分类算法了,这个算法读入之前特征工程产生的特征并作出预测,就是这么简单:
probas_ = classifier.fit(X_train, y_train).predict(X_test)
机器学习的这些分类算法模型做的工作可以认为是利用每个例子的N个特征向量的权衡考虑得到预测结果。不同的分类算法的权衡考虑方法不一样,但是从总体来看是个多变量的平衡。因为本文重点在于特征工程,而关于模型的训练原理以及背后的数学可以说很多,在此就仅把模型训练当作黑盒处理,有兴趣的观众朋友们可以多多研究scikit-learn关于分类算法的教程http://scikit-learn.org/stable/tutorial/statistical_inference/supervised_learning.html。对于模型参数的选择可以通过交叉验证(Cross validation)来优选最适合的参数,这一点请当作进阶自行阅读。
一些个人的意见就是,各种分类算法的效果其实差不太多,区别主要在于适用情况上,如果发现一种分类算法的结果明显不满意,可能是因为它不适合这个问题(比如朴素贝叶斯就不适合特征相关度高的),也有可能这个算法需要的特征还没被挖掘出来,需要回到特征工程上面再深入挖一些有利于区分正例反例的特征。总的来说,特征工程弄好了就定好了分类效果的上限,模型只是尽力接近这个上限,多花时间在搞特征上最能提高。除非是深度学习这样带特征学习的猛兽,这就是题外话了。
0x05 评价函数和交叉验证
为了评价机器的预测效果,我们需要量化的评价函数。对于“判断域名是否为C&C”的问题可以考虑:
- 对于真正的C&C域名能抓住多少,多少漏网?(true positive vs false negative用召回率recall衡量)
- 如果一个域名是合法域名,会不会当作C&C误杀?(true positive vs false positive用精度precision衡量)
关于precision(精度)和recall(召回率)的相关介绍,请参见wikipediahttp://en.wikipedia.org/wiki/Precision_and_recall计算precision和recall的代码很简单:
from sklearn.metrics import precision_recall_curve
precision, recall, thresholds = precision_recall_curve(y_truth, probas_)
在训练模型的时候,测试数据对我们并不可见(否则就不叫预测了,就是作弊啊),那么问题就是,只有训练数据我们怎么评价我们的模型的预测效果呢?一个好用的技术叫做交叉验证(Cross-validation),基本方法就是假装看不见一小部分训练数据(一般是1/5),用剩下的4/5数据训练模型,看看这4/5数据训练的模型对那1/5的数据的预测能力,因为那1/5的数据我们知道它里面那些域名是C&C哪些不是,这样就可以计算precision和recall。为了公平起见,一般我们会把数据随机洗牌,然后做多次交叉检验,这叫做K-fold cross validation。
对于每次的交叉检验,我们可以画出precision vs recall的曲线图,从中可以看到precision和recall的相对平衡,比如下图:

我们可以看到,如果要保持0.8左右的recall召回率,precision可以达到90%以上,但是如果要召回率达到100%,那precision只能有15%左右了。
域名的分类效果和域名的长度也有关系,我们可以画出来平均的Accuracy和域名长度的关系图:
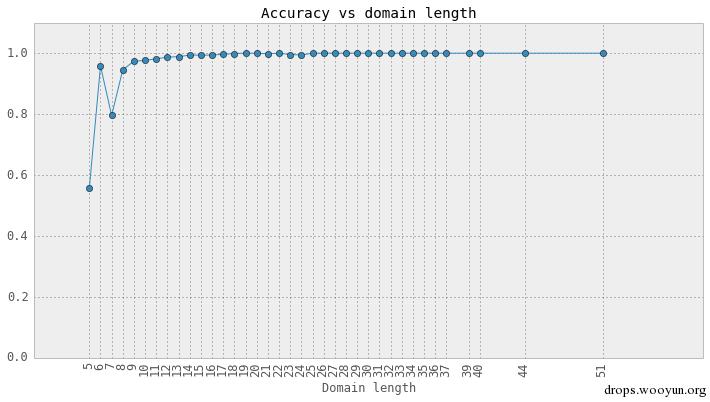
正如大家想到的一样,对短的域名分类效果一般,因为短域字符串本身的信息不如长域名丰富。不过现在C&C的域名越来越长,如果只看长于12个字符的C&C域名,预测效果还是很不错的。
值得提醒的是,测试数据的预测误差比交叉检验得到误差不同(一般测试的误差要大得多)。在测试数据上的误差需要深入的了解和调试,这些是进阶内容,请今后自己在实战里摸索,很有挑战性哟。
0x06 总结
这篇文章用域名字符串特征判别C&C的任务,简单介绍了一下机器学习在安全领域的一个小小应用,主要为了演示一下一个机器学习任务的基本流程。在机器学习里,特征工程几乎是最重要的部分,在这篇文章里面我们深入挖掘了“看起来像”这个分类特征的若干种可以量化的表达方式,有些特征需要反复思考得到,有些特征需要领域知识。对于输入的一组很好的特征,基本上各种分类器都能有不错的表现,我们用精度和召回率评价模型的分类效果,看看有哪些C&C我们放过了,哪些合法域名我们误杀了,用交叉验证的方式判断模型效果,并根据这些评价来调整模型。更简单一点就是这个套路:
- 准备数据集
- 抽取特征(几乎是最重要的工作)
- 选取合适的模型(绝大多数情况都有开源的代码)
- 设计评价函数并交叉验证(设计一个适合自己问题的评价)
- 对测试数据预测
在实际工作里,2-5这几步可能需要反复完善:用基准特征训练模型,用交叉检验搜索选择最优模型参数并评价,如果评价不满意,继续添加新的更好的特征,如果添加特征还不满意,就再继续调整模型参数添加新的特征,挤一挤总是有的嘛。
在安全领域很多方面都可以用机器学习来辅助,比如从日志里挑出可疑行为,在exe文件里找出malware的hook插入点之类的,都遵循上面类似的套路。这篇文章想起到抛砖引玉的作用,给各位白帽专家做参考,看看机器学习在你们的特定专业领域里应用。在我的实际工作里,机器学习的多方面技术都有应用,比如可以用clustering聚类的办法把可能的botnet聚集在一起,用遗传算法反解出散列攻击的随机数生成算法,用深度学习做(此处被公司要求马赛克掉)的一些研究。
提醒一点的是,机器学习的主要目的是简化和辅助而不是取代专家的工作,它可以减轻白帽专家批量处理一些繁复复杂问题的负担,让专家集中精力到更重要的工作上,它的预测判断基于一定的前提条件,预测的结果是0-1之间的概率。对于一个可能C&C域名是杀是放,还是取决于执行最后决策的人类白帽专家。你问我支持不支持机器的预测,我是支持的,但是一切还都要按基本法来,对吧。
安全的工作好比大海捞针,机器学习可能就是帮我们捞针的磁铁,欢迎大家加入机器学习的行列。
0x07 深入阅读和参考文献
从域名的“看起来像”这个特征来判断C&C域名的想法受到这片文章的启发http://www.sersc.org/journals/IJSIA/vol7_no1_2013/5.pdf
如果想继续学习一些关于机器学习的知识,建议在Coursera上学习斯坦福的机器学习入门课https://www.coursera.org/course/ml
机器学习在安全领域有很多应用,比如Kaggle的Malware分类任务,机器可以分析反编译的ASM和原始binary自动判别malware的种类并取得很好的效果,几位获胜者的报告很值得研究一下https://www.kaggle.com/c/malware-classification
在Kaggle比赛和本文中用到的机器学习软件包 scikit-learn 的主页在http://scikit-learn.org/stable/(已被墙)